




基于作业成本法和BP神经网络的项目成本预测
一、引言
过去三十多年,中国高科技产业飞速发展,不断带动经济朝着更健康的方向发展,成为中国产业结构调整的中坚力量。但是,高科技产业在成本管理方面面临着更加严峻的挑战,以往传统的项目成本管理模式单调滞后,通常只有事后成本的计算,不利于成本的预算和差异分析。
随着高科技产业发展进入新阶段,上述成本管理方法已经不符合高科技公司的需要。因此,必须更换成本管理方法,引入新的管理办法——作业成本法(activity based costing)。作业成本法是根据事物的实质特征,运用数理统计方法,进行统计、排列和分析,抓住主要矛盾,从而有区别地采取管理方式的一种定量管理方法。这种方法适用于不能依靠单一因素对复杂生产过程进行成本分配的高科技产业。本文尝试用此法作为成本分配的基础进行成本预测。
人工智能普遍应用于各行各业,会计行业也在不断探索人工智能的潜力。本研究尝试将监督式学习运用到企业的项目成本预测中,让计算机根据公司全成本系统中记录的以往成本和作业信息的标准答案进行学习,通过比较测试集的计算机预测结果与标准答案之间的差异,不断调整算法模型的参数,使得计算机的预测结果逐渐提高准确率,从而靠近标准答案,以实现未来对新项目成本的预测。根据预测结果可以进行后续的项目选择和定价,实现人工智能在公司管理会计运用上的突破。
在实践中,公司可以在考虑成本效益原则的基础上,尽可能多地建立作业成本库,从而使模型的预测更加精准,节省公司人力财务成本,带来预期收益。
二、案例描述
(一)案例企业背景
河北某科技有限公司2005年成立,注册资本200万元,主要经营天线自动测量设备、雷达遥控遥测设备、天线系列产品、软件研发、射频网络应用产品的设计、生产和服务,被河北省科学技术厅认定为河北省高新技术企业。对一个正在发展中的高科技公司来说,准确预估项目成本从而选择出正确的可带来预期收益的项目,并进行准确定价是公司能否实现资金流通,从而得到良性发展的关键。本文尝试运用作业成本法先将所选公司的项目成本划分成若干成本作业库,找出成本动因,再利用BP神经网络在学习历史数据的基础上对未来项目成本进行预测,使得案例公司的项目成本预测更加准确。
(二)原成本核算存在的问题
案例公司所采用的传统的成本核算方法将制造费用按照每种产品所耗用的直接人工(或机器小时)分配到产品中去。这种方法的隐含假设是制造费用的消耗与生产的各产品的产量成正比,因而成本分配是否正确就取决于制造费用是否真正与产量相关。如果各产品消耗的制造费用恰好与其产量成正比,那么传统的成本核算方法既正确又简便。但实际上,产品的差异性很大,导致其生产工艺的差异化,不同的产品型号、不同的采购需求、不同的技术人员需求等都会导致产品以不同于产量的比例来消耗制造费用。因此,生产工艺复杂而产量较小的产品可能分配到较少的成本,生产工艺简单却有较大产量的产品可能分配到大部分的成本。这会导致成本的分配与实质严重不符,不仅会影响产品定价,还会影响管理者进行正确的经营决策。
(三)作业成本法和BP神经网络结合的适用性
1.作业成本法在高科技企业的适用性
作业成本法在高科技企业计算成本时得到的结果更加准确。作业成本法在核算成本时能够关注成本产生的本质原因,从根源入手,对高科技企业这种成本诱因繁杂的产业更为适用,计算出的成本更加符合实际。同时,高科技企业的飞速发展伴随着工艺流程的不断更新变化,作业成本法可以更好地反映这种变化。而传统成本法无法辨别。
作业成本法更适合高科技企业的要求。经济的发展对高科技企业提出了更严格的要求,仅仅依靠产品更新换代来促进企业发展是不够的,企业还需关注成本管理。而对于高科技企业来说,工艺流程是十分重要的。与此对应的是间接成本的控制,作业成本法在核算间接成本方面的优势较大,更适合其成本管理的需求。同时,企业可以利用准确的计算结果来进行生产决策或制定定价战略。
作业成本法可以有效利用企业搜集整理的大部分信息。随着会计电算化和信息系统的不断发展,高科技企业在信息系统的使用上更具优势。传统成本计算方法只能简单利用产量等最基本的信息。相比而言,作业成本法因为成本动因的存在,可以利用更多的存储于信息系统中的信息。
作业成本法拓宽了成本核算范围。作业成本法以作业为基础进行成本核算,可以将传统成本法中归属于固定成本的成本纳入核算范围,使项目的成本核算成为真正的全成本核算,对项目的盈利分析或是定价战略更有利。
2.BP神经网络与作业成本法结合的可行性
BP(back propagation)神经网络适用于非线性关系,符合成本动因与成本之间的关系。传统的成本计算方法认为,产量等分配标准与成本是呈线性变化的,普通的作业成本法在利用成本动因分配成本时也隐含了一个假设:成本动因与相应的作业成本之间是线性关系,但实际上引发成本发生的动因不一定与成本呈线性变化。神经网络具有的非线性映射特点可以弥补这一不足,探索成本动因与成本之间实际的关系,更加接近成本发生的本质。
BP神经网络无须每个作业成本库的成本数据,可以简化计算并减少差错。在利用BP神经网络算法进行预测时,只需要输入成本动因数据,并不需要相对应的每个作业成本库的成本数据,输出的成本直接是间接总成本。这种模式使得企业在运用作业成本法时,省略了将成本根据资源动因归集到作业成本库的步骤,不仅简化了计算,而且减少了分配资源时可能产生的错误分配。另一方面,如前文提到的管理/支持类费用,需要根据资源动因归集到各作业成本库,计算复杂,但是利用BP神经网络就可简化这一步骤。
BP神经网络不需要成本动因和作业成本库之间的一一对应关系,更符合成本发生的本质。在实际情况中,某一作业成本库的成本动因不仅对这一作业成本库起作用,也可能与其他作业成本库有关。BP神经网络考虑到这一点,直接研究所有成本动因和总成本的关系,可以将这一问题的影响最小化。另外,利用BP神经网络可以选取尽可能多的成本动因,甚至与成本有关的任何数据都可以作为输入变量,使模型更加接近实际的成本发生规律。
BP神经网络可以大大简化作业成本法的计算。神经网络在学习标准数据后,可以记忆误差最小的模型,之后进行成本预测时此模型可以直接使用。只要未来成本发生规律与总结出的规律没有差别,模型一直适用。预测过程不再需要人工的大量计算,这不仅减少了工作量,而且降低了差错率。
(四)新成本核算与预测模型的搭建
1.作业成本法的实施
公司进行成本核算时以工程项目为核算对象,工程项目的全流程如图1所示,图中所示人工工时仅为假设。
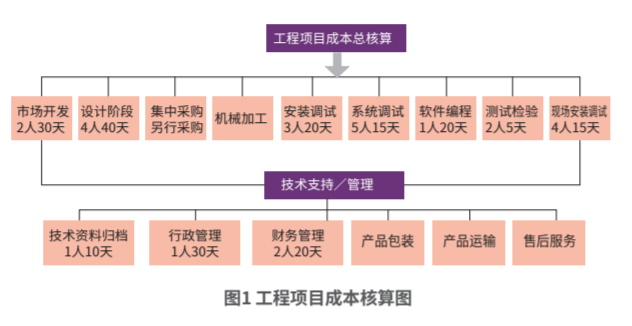
在选择作业成本库时可以根据工程项目的流程来划分,因此在进行作业成本归集时也按照每一流程进行归集。
成本动因的选择至关重要,关系到成本计算的准确性。在选择成本动因时,既要考虑所选诱因与该作业成本的相关性,又要考虑成本效益原则。如果选择的一个最准确的成本动因需要耗费大量的资源来进行信息收集,则反而会增加成本核算所花费的成本,并不利于企业的成本管理。因此,在选择公司成本动因时,应始终考虑四个原则:重要性原则、相关性原则、充分性原则和成本效益原则。
本文所选公司项目的主要生产流程可以作为作业成本库,各类资源可以根据资源动因归集到作业成本库中,再根据作业成本库的特征选择合适的成本动因,如表1所示。
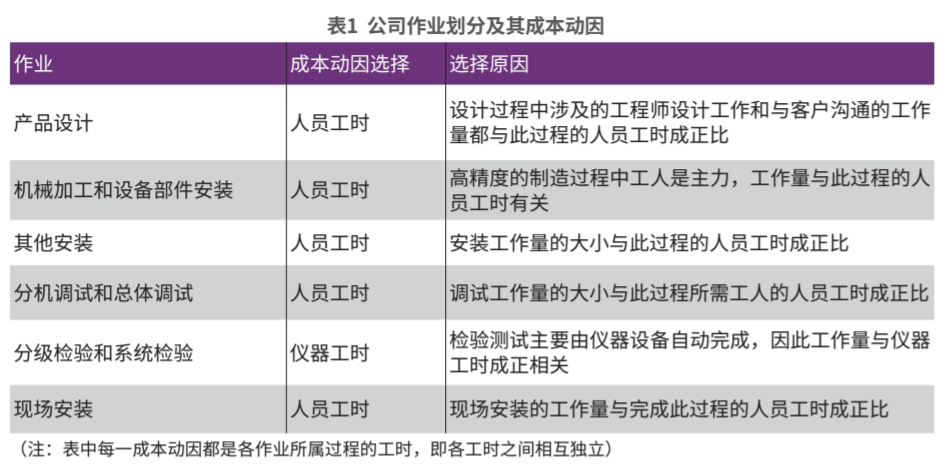
产品设计作业包括总体方案设计、机械结构设计、伺服电器设计、通信信道设计及软件设计等;在设计过程中,包括技术指标和客户沟通及设计方案评审等。这些设计工作都是由高级工程师完成的。所以,根据相关性原则,此过程的工程师人员工时是最相关的成本动因。另外,工程师的工时有详细的记录。此信息收集较为简便,符合成本效益原则。
制造作业指产品主要生产作业,主要包括机械加工和电器设备部件安装等。本文案例公司生产高精度航空产品,制造过程主要由工人操控设备或直接由人工完成,成本的发生与工人人员工时直接相关,并且人员工时是最重要的成本动因,因此选择制造过程中工人的人员工时作为此作业的成本动因。
安装作业是指系统设备总体安装,如天线座架安装、伺服驱动控制单元上架等。与制造作业类似,安装作业由工人作业。该过程人员工时是最直接的成本动因。
调试作业包括分机调试和系统总体调试。该作业需要工人利用仪器设备完成工作,主要工作仍由工人进行,仪器设备是辅助。因此,该过程人员工时是最重要最相关的成本动因。
检验作业包括分机检验和系统检验。系统检验分出厂检验和用户交验,检验主要是天线座架功能检验、精度检验及电器设备功能、技术指标测试检验。该作业自动化程度高,主要依赖仪器设备进行自动的检验工作。选择仪器工时作为该作业的成本动因更符合相关性原则。
现场安装作业是指设备安装测试检验,最终用户验收。该作业由工人上门进行安装服务,因此人员工时是该作业直接的成本动因。
对于各项目所耗费的直接材料不作为作业成本法核算的成本对象,将从总成本中扣除。
对于技术支持和管理所花费的各类费用,因为无法准确分摊到各项目成本中,所以首先根据资源动因先归集到各作业中,再通过作业分摊到项目成本中。
2.BP神经网络的构建
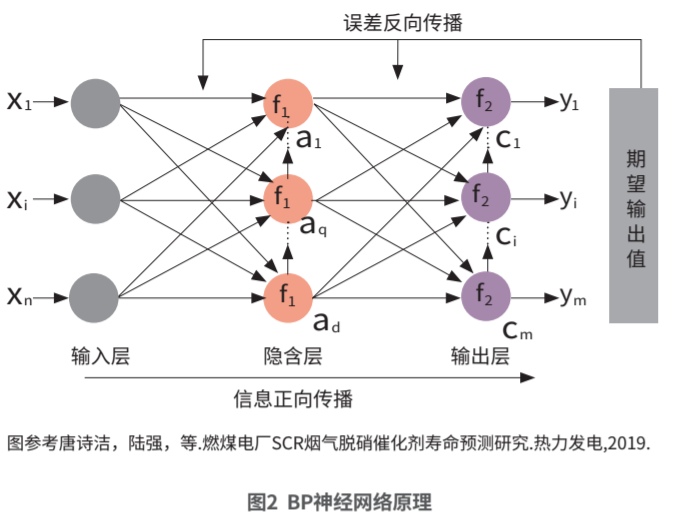
BP神经网络是一种具有误差反向传播特点的多层前馈神经网络。BP神经网络由输入层、隐含层和输出层构成,其中输入层和输出层只有一层,隐含层的层数可以根据实际需要设置。此算法包括两个基本过程:信息正向传播和误差反向传播。算法通过输入和参数(权值、阈值)计算输出值,此过程是从输入到输出的方向,属于正向传播;而根据预算和实际的误差反馈调整参数的过程是从输出到输入进行,属于反向传播。前馈传播时,模型通过非线性关系产生预测值,若预测值与期望输出误差较大,则转入反馈传播过程。误差反向传播是把误差反向传到隐含层和输入层,并分摊到各单元,作为调整各层各单元参数的依据。通过此过程的反复学习训练,可以确定一个包含最小误差参数的模型,训练停止。利用此调整好的模型可以进行未来数据预测,输入相应的数值可以得到输出的预算值。过程详解如图2所示。
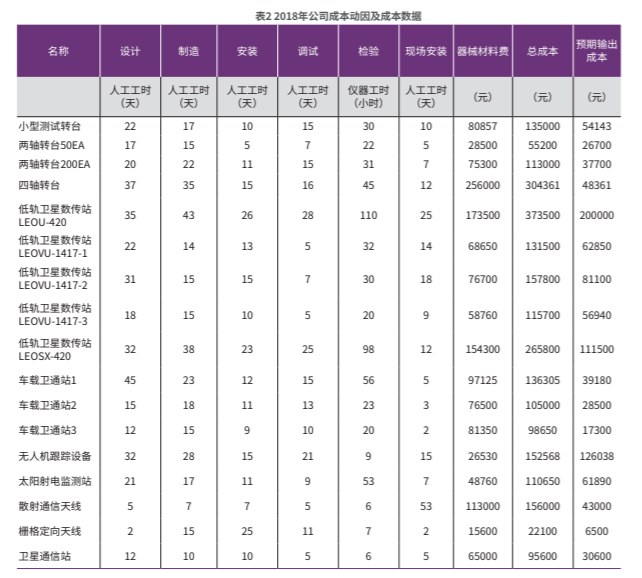
本文拟通过河北某科技公司作为研究对象,需要的所有数据来源于案例公司财务系统和公司管理层。为了使得成本预算更加契合当前情况,本文选取了河北某科技公司2018年全部项目的成本数据作为机器学习的基础,这些数据包括每一项目的实际总成本和直接材料成本,以及挑选出的成本动因作业量:设计、制造、安装、调试、现场安装阶段的人员工时和检验阶段的机器工时。具体数据见表2。
根据上文的BP神经网络原理,可以建立基于作业成本法的成本预测模型。在神经网络的结构设计中,输入层单元数为6。输出层只设置一个单元,即除了直接材料成本外的其余成本,也是最终要预测的成本数值。通过上述设置,可以构建一个6×N×1的神经网络模型。其中,N为隐含层单元数,实际运行时先设置一个经验值,后续通过不断修改来得到准确率更高的数值。
3.模型的实际运行①
第一步:读取目标文件。文件中包含17条训练集和测试集所有输入层成本动因数据和输出层成本数据。其中前16条为训练集,最后一条为测试集。模型构建所用到的Python程序代码如图3所示。
df1 = pd.read_excel('data.xlsx')
yyT=df1['输出'].values

第二步:将数据进行归一化处理。因为输入的样本性质、标准等各方面有些差别,可能会使神经网络进行错误判定。将数据归一化处理目的是增加神经网络学习的准确性,避免因数据单位、性质不同而影响数据处理结果,同时可以提高数据读取和处理的速度。归一化处理公式为:
Y=(xi�6�1xmin)/(xmax�6�1xmin)
此步骤的代码如图4所示。
df = (df1-df1.min())/(df1.max()-df1.min())
data1=df.values
data=[]
for i in data1:
data.append(i[:-1])
yy=df['输出'].values

第三步:结构选择。输入层6个变量,输出层1个变量,隐含层设置为20个变量(隐含层单位数没有统一要求,需要根据不断测试得出,20是使训练误差最小的单位数)。学习率设为0.001。如图5所示。
l1 = add_layer(xs,6,20,activation_function=tf.nn.relu)
pred = add_layer(l1,20,1)
tf.add_to_collection('pred_network', pred)
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys -pred),reduction_indices=[1]))
train_op = tf.train.AdamOptimizer(0.001).minimize(loss)

第四步:防止过拟合数值设为1,即不用防止过拟合。因为本例数据量较少,应充分利用所有数据,因此不用防止过拟合。理论上训练次数越多拟合效果越好,但是当训练次数增加对准确度不再有影响时应停止迭代。训练次数首先设为10000,后经过不断修正,当训练次数为12490时最终误差较小,因此设为12490,如图6所示。
keep_prob=1
ITER =12490

第五步:将整个学习和测试过程进行定义,并根据定义运行算法。如图7所示。
def fit(X, y, ax, n, keep_prob):
init = tf.global_variables_initializer()
feed_dict_train = {ys: y, xs: X, keep_prob_s: keep_prob}
with tf.Session() as sess:
saver = tf.train.Saver(max_to_keep=1)
sess.run(init)
for i in range(n):
_loss, _ = sess.run([loss, train_op], feed_dict=feed_dict_train)
if i % 50 == 0:
#print("epoch:%d\tloss:%.5f" % (i, _loss))
y_pred = sess.run(pred, feed_dict=feed_dict_train)
try:
ax.lines.remove(lines[0])
except:
pass
lines = ax.plot(range(16), y_pred, 'r--')
plt.pause(1)
pre = sess.run(pred, feed_dict={xs: X_train,keep_prob_s: keep_prob})
kk=1
for uu in pre:
mm=uu*(yyT.max()-yyT.min())+yyT.min()
print("epoch:%d\tprediction:%d\tloss:%.5f" % (kk,mm, _loss))
kk=kk+1
fit(X=X_train,y=y_train,n=ITER,keep_prob=keep_prob,ax=ax)

打开Anaconda② 中的Spyder 应用,输入上述代码并运行。可以观察到模型根据训练数据开始学习,通过误差反向传播,模型拟合的误差越来越小。
因为数据量较少,对模型进行测试时将所有数据都进行测试。首先测试训练集的16条数据,再利用测试集进行测试。训练集和测试集的模型预计结果如图8所示,与实际结果的误差如表3所示。

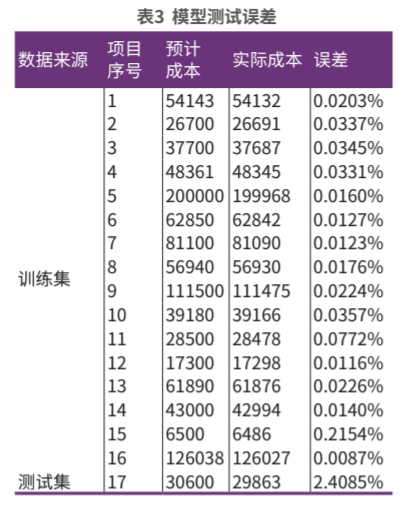
模型对测试集16条数据的预测值准确度都很高,误差全部控制在0.3%以内。最终模型预测的测试集输出值为29863,与实际的期望输出值30600相比,误差为2.4%。可以看出,该模型对17条数据的预测误差率都保持在低水平,可以终止训练过程。
保存好训练好的模型,可供未来成本预测时调用。
4.模型的优化
以上是对2018年17条项目成本数据的模型试验,下面考虑使用2019年已完成的三个项目的成本数据再进行模型优化。利用上述训练好的模型测试2019年的三条项目成本数据如表4所示。
可以看出,模型测试出的预计结果和实际成本之间误差较大,说明用2018年数据训练的模型并不适用于2019年的成本预测。因为各种人工成本、机械成本和加工成本也会随时间变化而变化,较远的历史数据不能直接用于未来的成本预测。
考虑将此模型进行优化,将2019年的前两条项目成本数据也加入训练集,重新训练模型,其余参数设置同上文所述。再利用剩余的2019年最后一条成本数据对重新训练好的模型进行测试,得到的结果如图9所示。
epoch:1 prediction:63259
loss:0.00000

预测的成本和实际成本之间的误差为3.19%,误差在可接受范围之内,说明模型利用新成本数据进行不断训练可以增加模型的准确度,离需要预测成本的时间越近的成本数据对模型的建立越重要。
5.运用模型进行成本预测
对未来项目成本进行预测,首先需要预测未来项目的成本动因量。本文采用作业成本法和BP神经网络结合的模型进行成本预测,以2019年项目成本预测为例,将该项目之前相对较近的成本数据作为训练集对模型进行训练,并测试误差,得到误差率最小的模型。利用该模型对未来的项目成本进行预测。相关的代码如图10所示,在第103行中输入成本动因数据,但需要将数据进行归一化处理后再输入,得出的结果即为项目成本预测数。
with tf.Session() as sess:
new_saver = tf.train.import_meta_graph('mm/model.meta')
new_saver.restore(sess, tf.train.latest_checkpoint('./mm/'))
y = tf.get_collection('pred_network')[0]
graph = tf.get_default_graph()
input_x = graph.get_operation_by_name('xin').outputs[0]
keep_prob = graph.get_operation_by_name('kp').outputs[0]
xa=np.array([12,2,3,4,5,6],[1,2,3,4,5,6]).reshape(-1,1)
ap=sess.run(y, feed_dict={input_x:X_test, keep_prob:1})
ap = ap * (yyT.max() - yyT.min()) + yyT.min()
print(ap)

三、结论与展望
随着市场竞争的日益加剧,企业不仅需要提升产品方面的优势,而且加强成本管理的需求更加紧迫。本文尝试将作业成本法与BP神经网络结合,首先利用作业成本法辨别作业成本库和相对应的成本动因,再用神经网络根据已有的训练数据探究成本动因与成本之间的非线性关系,根据测试数据对模型不断进行调整优化,模型的误差控制在4%以内,最后可以利用训练好的模型并进行后续的成本预测。
通过前述的理论分析和实证研究,利用BP神经网络和作业成本法对公司进行成本预测是可行的,且预测结果与实际值误差较小,本文所选方法可行。但是此法仍具有一定的局限性,例如:数据搜集要考虑成本问题,必须符合成本效益原则;模型需要时时更新以维持低误差率;标准数据是否准确关系到模型最终的训练效果;模型在成本预测中的应用还不够成熟,导致模型建立需要更多的时间精力;等等。所以,构造一个成熟的、准确度高、可值得完全信赖的模型还需要很多努力,目前只是处于理论分析和个别实践的探索阶段。
在未来的实践中,随着企业信息系统的完善,可以以较低的成本搜集到更多的成本动因信息。因此,可以设置更多的更准确的成本动因,增加模型精确度,使得运用此法进行成本预测可以成为主流的预测方法。企业也可以运用预测出的更准确的成本数据进行有效的成本管理,促进企业的良性健康发展。
......



